📃 Fast and Accurate Deep Bidirectional Language Representation for Unsupervised Learning 리뷰
얼마 전 TensorFlow Korea에 저자 분이 직접 설명을 간략하게 달아주셔서 읽어본 논문이다. ACL 2020 발표된 논문이고, Abstract에 Similarity task에는 BERT-based 모델에 비해 12배정도 빠른 속도를 가지면서도 괜찮은 성능을 가진다고 한다. 최근 Similarity Task가 필요해진 일이 있어서 리뷰해보았다.
간단하게 논문에서 필요했던 점만 적어본다.
Introduction
- “Can we construct a deep bidirectional language model with a minimal inference time while maintaining the accuracy of BERT?” -> 이 논문에서 주목하고 싶었던 주제
- 그래서 transformer를 사용해서 auto encoding을 했는데, 이 때 input을 복사해서 그냥 output에 낼 수 있으니 두가지 방법을 제시했다.
- diagonal masking
- input isolation
Related works
패스
Language Model Baselines
- speed baseline: Unidirectional language model
- performance baseline: bidirectional language model
Proposed Method
Transformer based Text Autoencoder
Diagonal Masking
- scaled dot product는 self-unknown이 잘 안됨
- transformer layer output의 각 position의 값은 \(Q\)와 \(K\)에서 나온 attention weight와 \(V\)의 다른 포지션의 가중합이 되도록한다.
- 인데 그냥 attention masking할 때 Identity Matrix를 추가해서 masking하는 것으로 이해하면 될 것 같다.
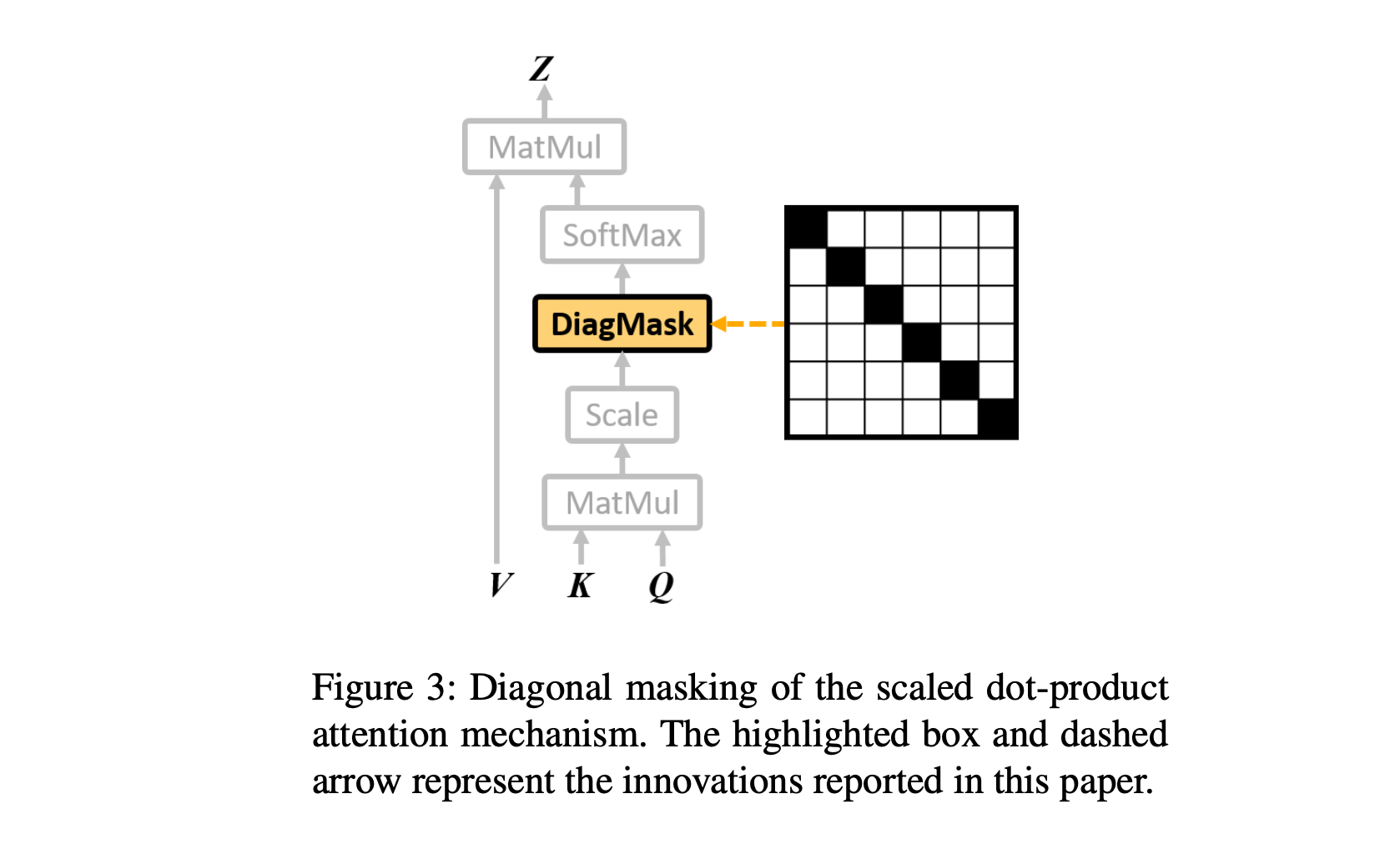
- 근데 이거 해도 residual connection 있으면 소용없음
Input isolation
- K, V 와 Q를 분리해서 넣어준다.
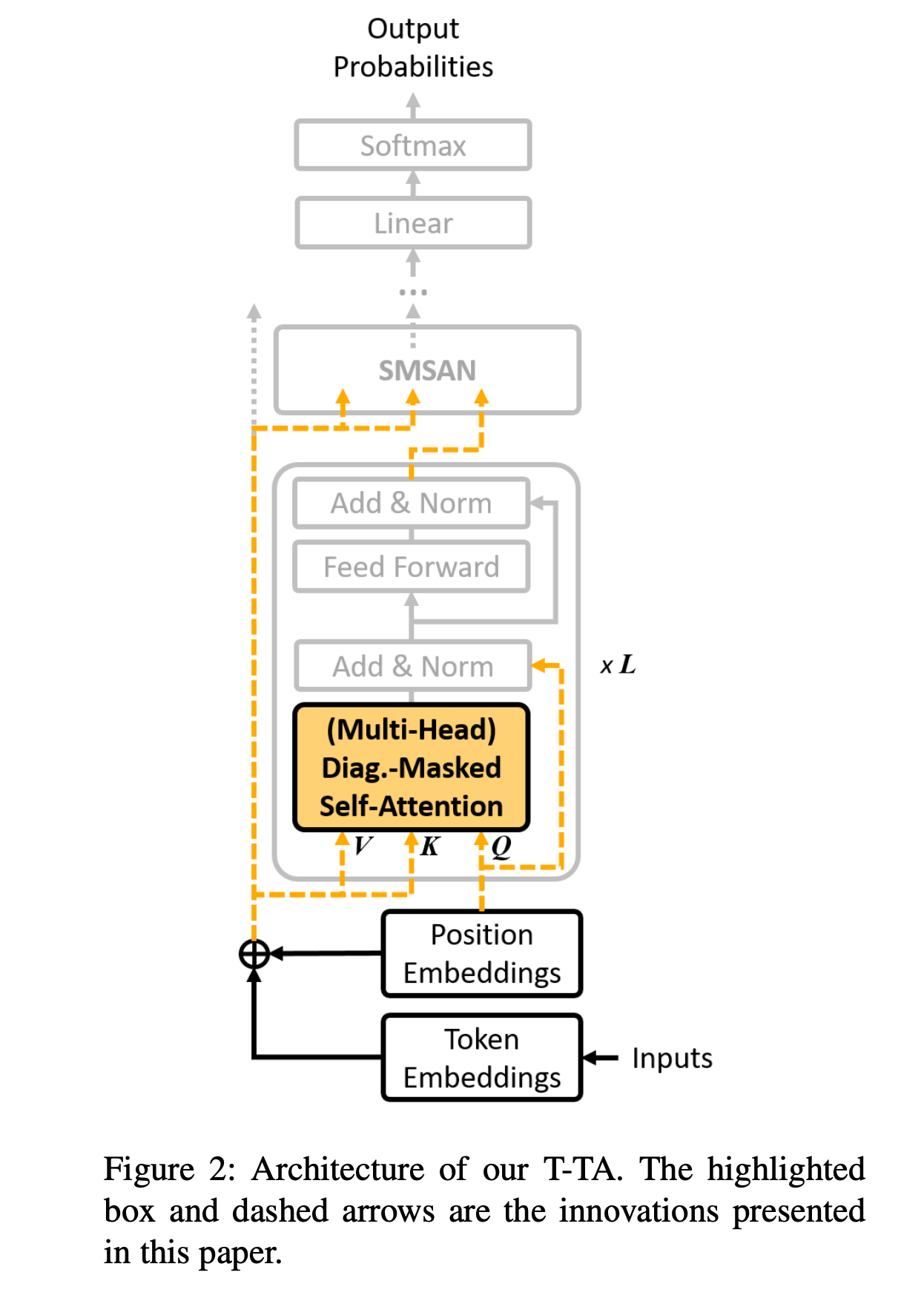
Experiments
다른 결과보다 Semantic Textual Similarity를 위주로 봄
- BERT Finetunining 없이 한 것 같은데, STS-B 기준으로 BERT보다 높게 나온다.
- 하지만 Sentence BERT (Reimers and Gurevych, 2019)논문에 기술된 스코어와 많이 차이나는 것을 보면 실제 BERT를 잘 이용한 것과는 차이가 있어 보인다.
- Transformer를 수정했다고 하더라도 3레이어만 사용했기 떄문에 당연한 것으로 보이기도 한다.
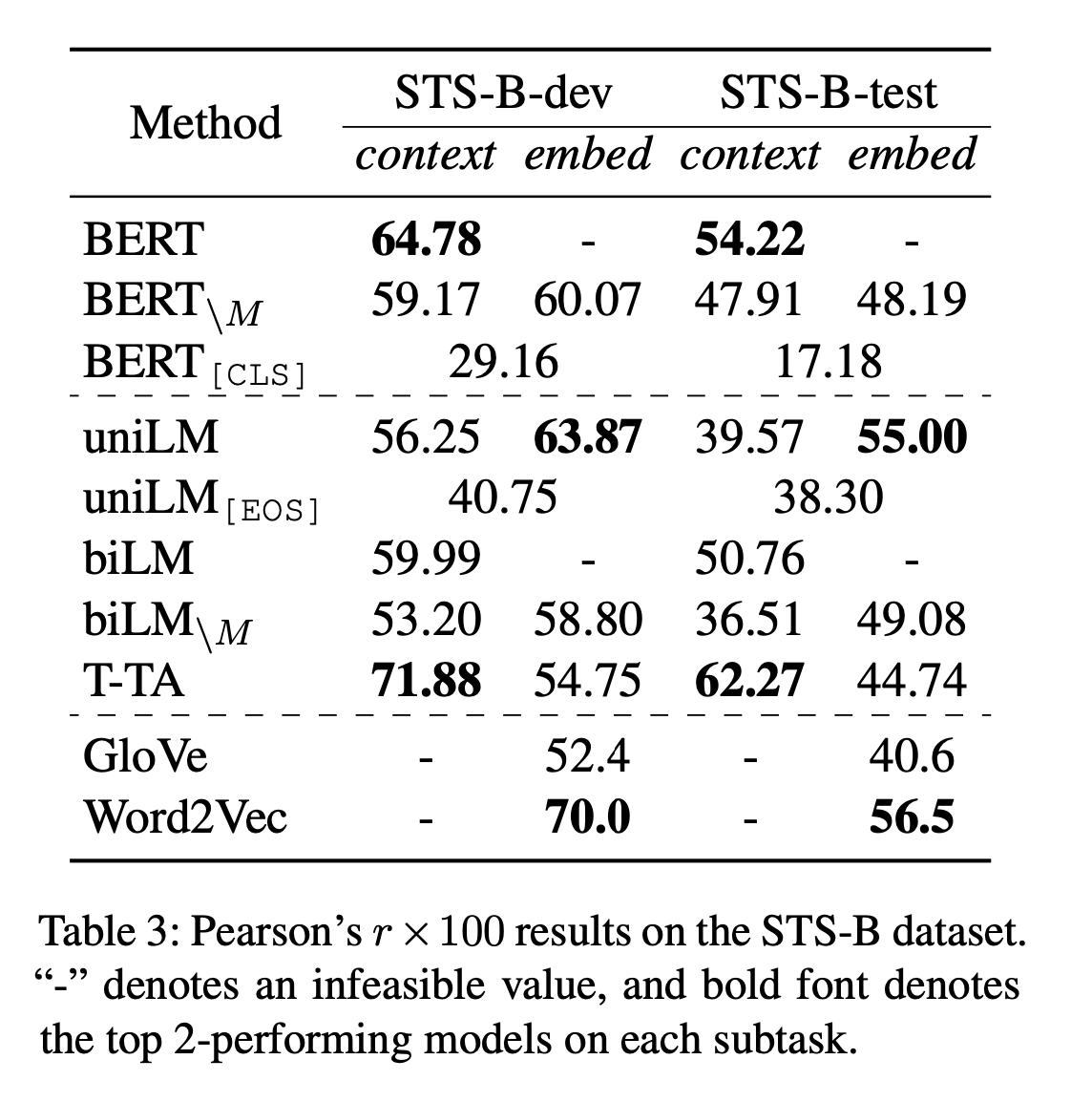
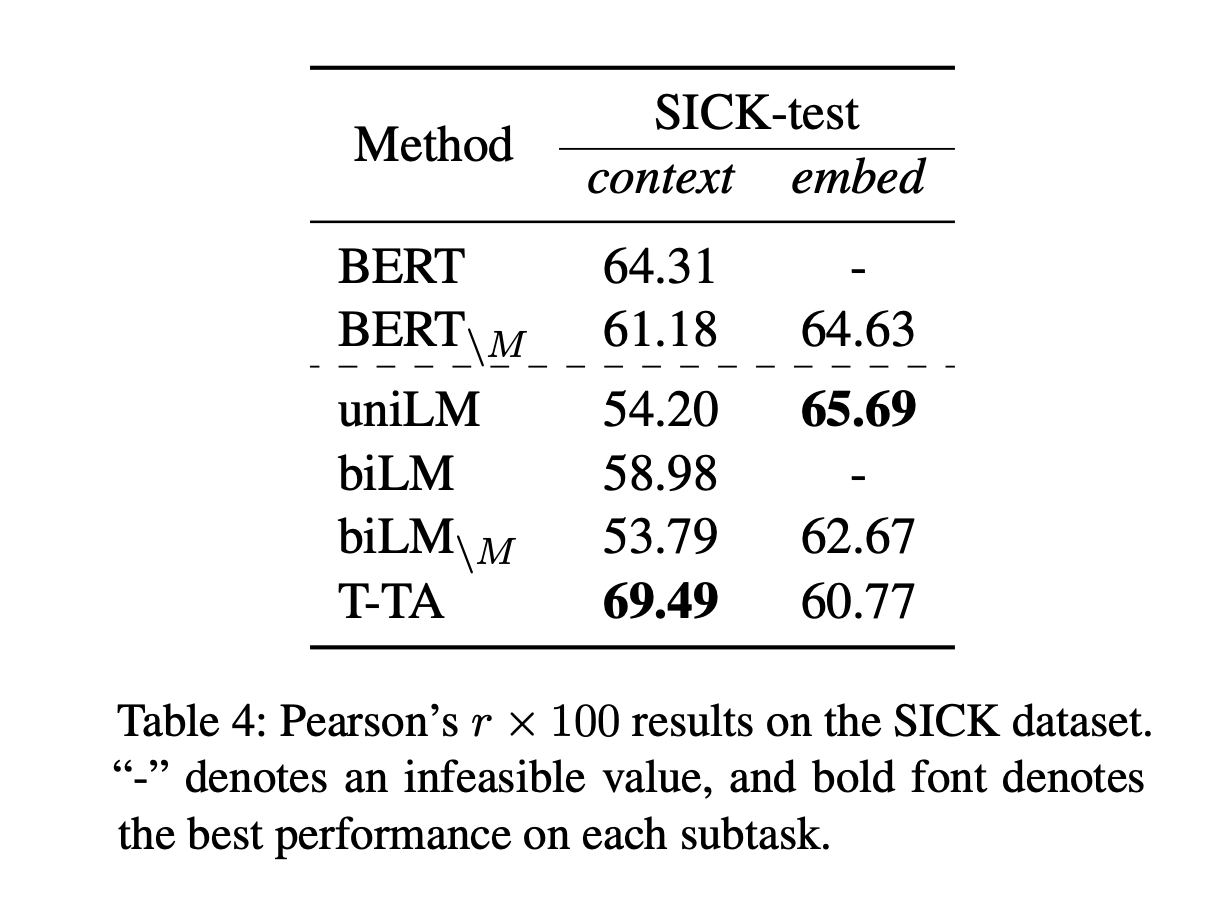
그래도 빠르게 뽑아내고 싶은 경우에는 괜찮은가?? 싶기도 하다.
January 1, 2020 에 작성
Tags:
paper